A corrida da inteligência artificial ganhou mais um capítulo nesta terça-feira: a Anthropic lançou o Claude Sonnet 5, novo modelo que a empresa descreve como o Sonnet mais “agêntico” que já produziu. O termo virou jargão do setor, mas a ideia por trás dele é simples — em vez de só responder perguntas, o modelo é capaz de planejar e tocar tarefas de várias etapas sozinho, abrindo navegadores, rodando comandos em terminais e usando ferramentas externas com pouca supervisão humana.
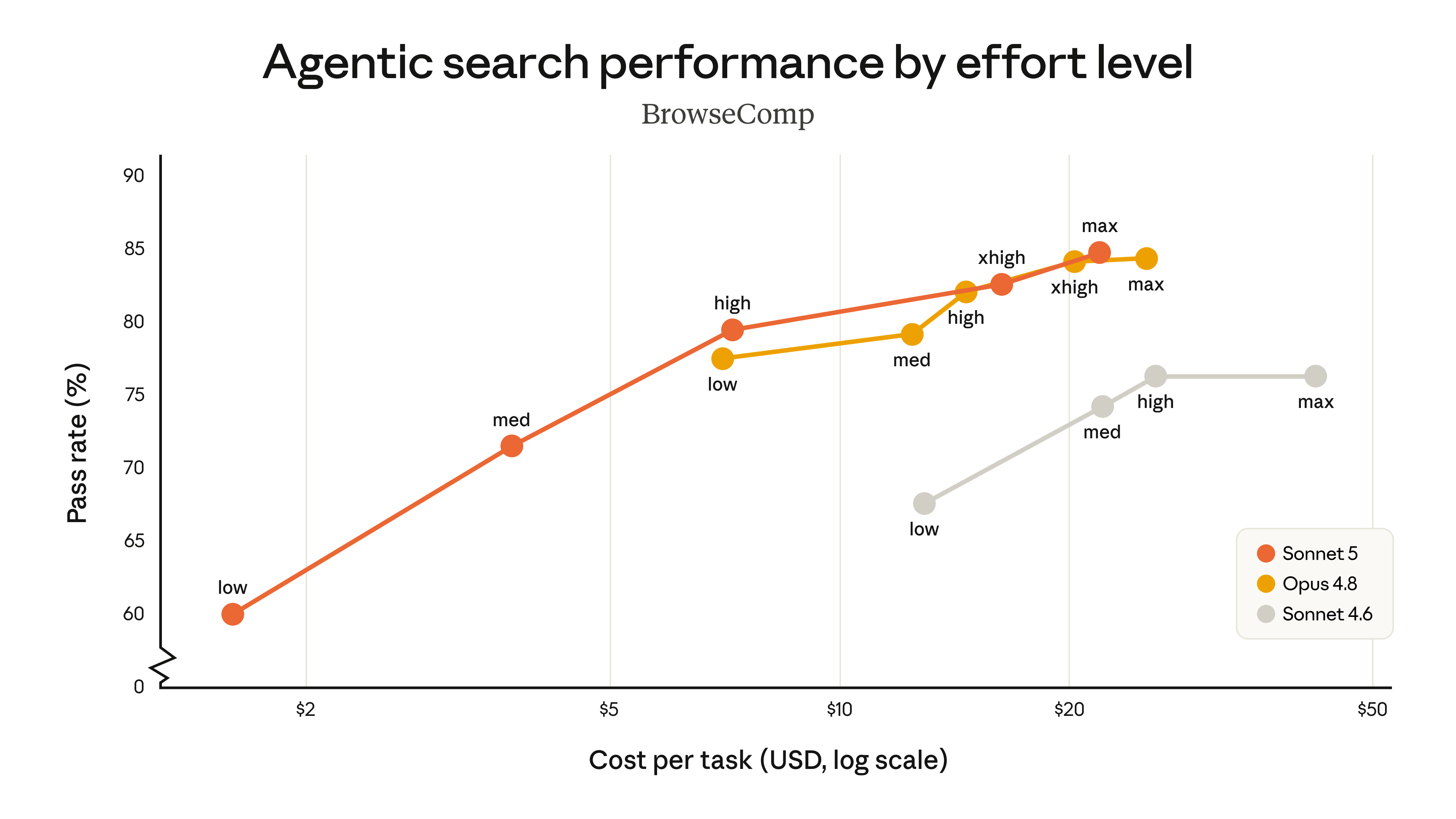
O ponto que mais chama atenção não é o teto de capacidade, e sim a relação entre desempenho e preço. Segundo a Anthropic, o Sonnet 5 chega perto do Claude Opus 4.8 — o modelo de topo da casa — em várias avaliações, mas custa uma fração do valor. É exatamente o tipo de movimento que a indústria vinha buscando: à medida que empresas e desenvolvedores colocam IA dentro de fluxos de trabalho reais, o custo por tarefa pesa tanto quanto a qualidade da resposta. Entregar quase o mesmo por menos dinheiro é o que torna o lançamento relevante.
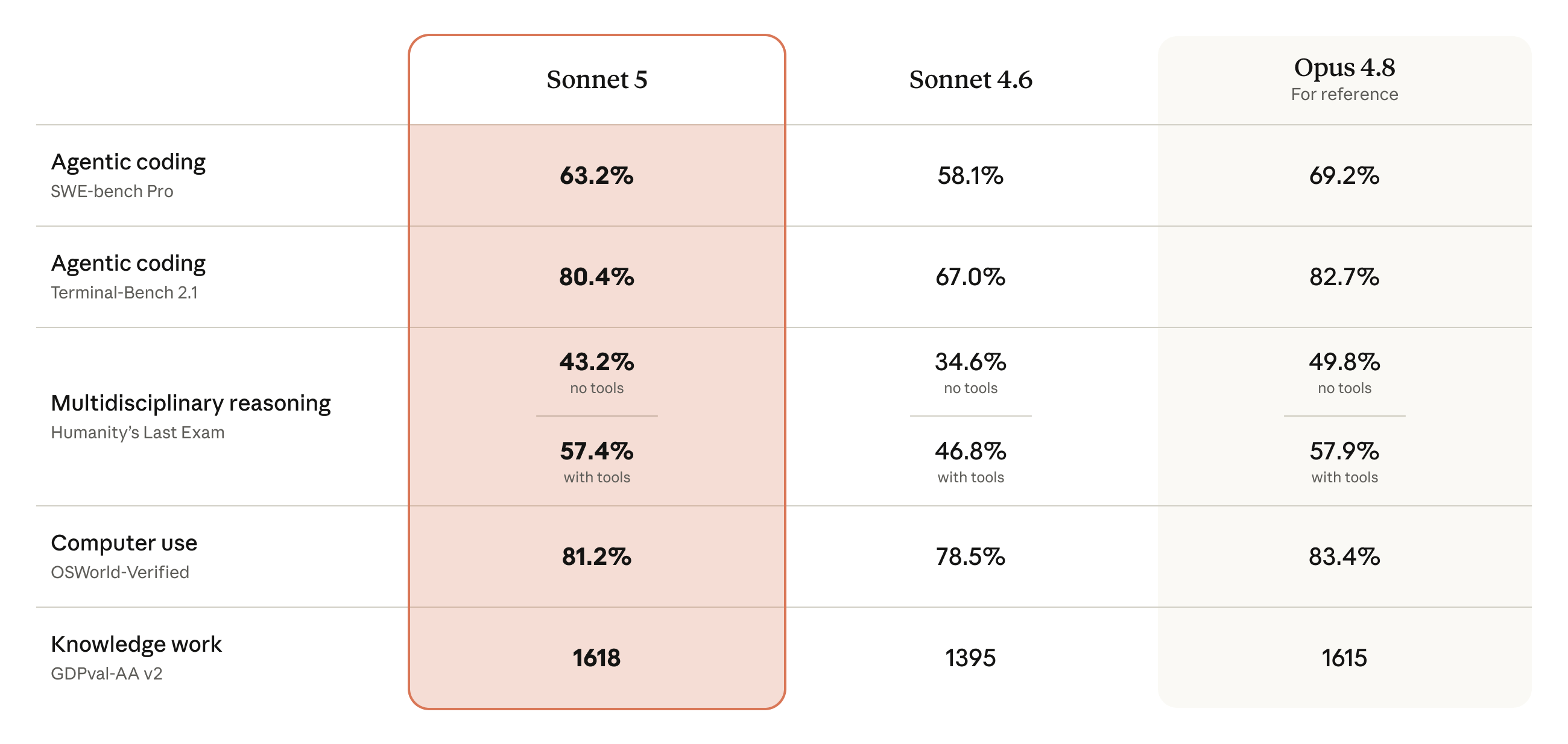
Os números ajudam a entender a aposta. Na API, o Sonnet 5 estreia com preço promocional de US$ 2 por milhão de tokens de entrada e US$ 10 por milhão de tokens de saída até 31 de agosto de 2026 — depois sobe para US$ 3 e US$ 15, respectivamente. A Anthropic destaca ganhos em raciocínio, geração de código, uso de ferramentas e em testes de navegação e controle de computador, como os benchmarks BrowseComp e OSWorld. O modelo também passa a ser o padrão para todos os usuários, do plano gratuito ao Enterprise, e responde pelo identificador claude-sonnet-5 na API.
Para o público brasileiro, o efeito tende a ser prático. Modelos intermediários mais baratos e capazes de trabalhar de forma autônoma reduzem o custo de automações, assistentes e ferramentas de programação que rodam por aqui — um alívio para quem paga em dólar. A empresa afirma ainda que o Sonnet 5 é mais seguro que o antecessor, com taxa menor de comportamentos indesejados, melhor recusa a pedidos maliciosos e maior resistência a ataques de injeção de prompt, mantendo travas que limitam usos sensíveis em cibersegurança. Resta acompanhar como o modelo se comporta fora dos testes controlados, no uso do dia a dia.